こんにちは! ヨス(プロフィールはこちら)です。
WEBの作成を依頼されたときに、元データ(テキスト)がPDFファイルだったことがあります。で、そのPDFファイルを開いて、文字データをコピーし、TeraPadみたいなメモ帳にペーストすると……なんと文字化け!
そんなときはAdobe Acrobatを使って「画像化+文字認識」で簡単に解決します。
目次
文字化け無しの文字をPDFからとる手順
文字化けしたPDFから文字データを取る方法は、簡単に言うと、PDFデータを画像データに変換し、今度は画像データの文字画像を文字として認識させるという過程です。
Adobe Acrobatを開き、PDFファイルをJPEG保存
まずは、Adobe Acrobatを開きます。そして文字データを取り出したいPDFファイルを開きます。
そして、下記の手順で別名で保存します。
別名保存する
以下の手順で別名で保存して下さい。
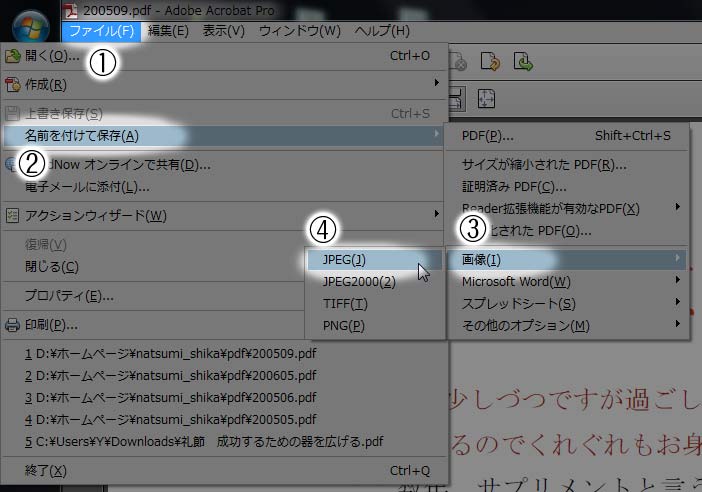
ドラッグしても選択できなく
JPEGで保存することで、一枚の画像として保存されます。
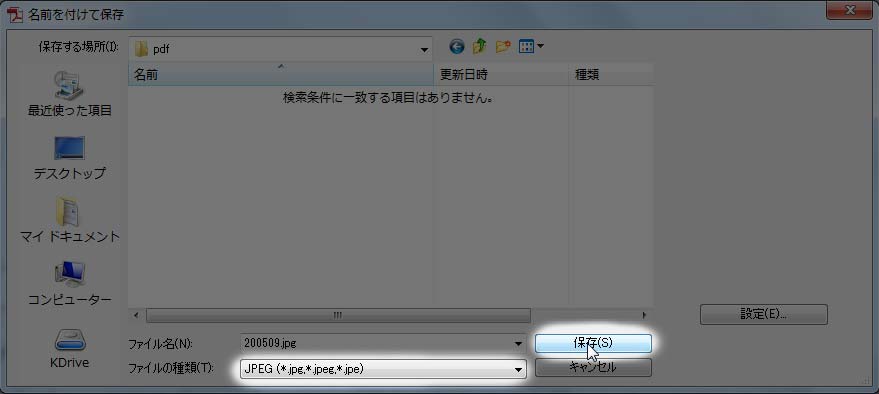
ここで文字が画像になるので、文字の上をドラッグしても文字として選べなくなります。
文字と画像化した文字の違いはこんな感じです。

この文字は画像なのでドラッグできません。
こちらは文字です。なので、ドラッグすると文字を選択できます。
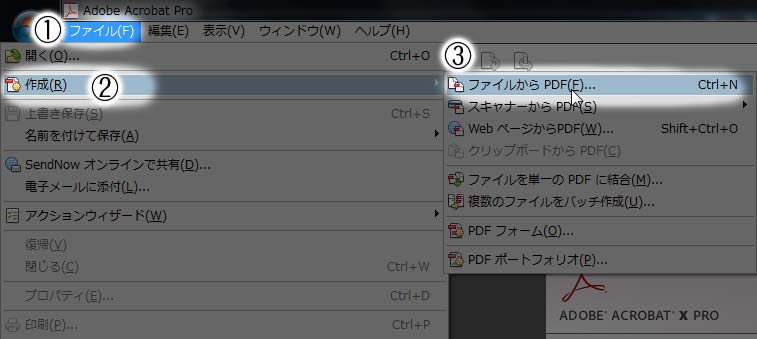
Adobe Acrobatで保存したJPEGファイルを開く
先ほど保存したJPEGファイルをAdobe Acrobatで開きます。ただそれだけです(笑)
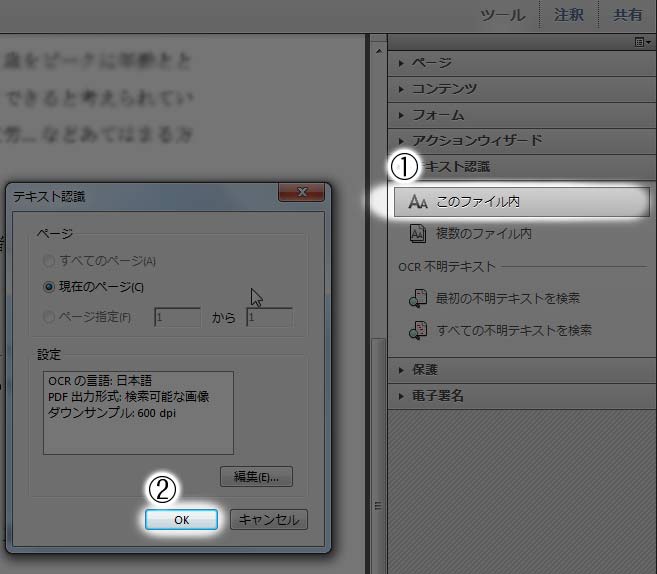
テキスト認識させる
テキスト認識とは、JPEGファイルのような画像データの中に入っている文字を「文字」として認識してくれる機能です。これによって、ドラッグ&コピーすることで文字をコピーできます。
このテキスト認識機能ですがスゴイ精度ですね。「☆」のマークが「大」になったり、「▲」のマークが「A」になったりしますが、ほとんどの文字は問題なく文字になります
!
テキストの認識
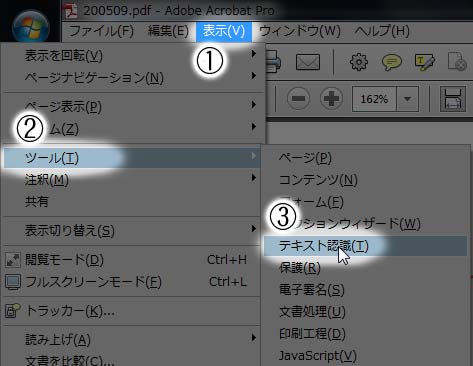
OKを押す
これで単なる画像だった文字が、ちゃんとした文字になりました!するとなんと!! 文字化けせずに文字を取れます!! やったね!
※2019年12月21日追記: 現在はスマホのOCRアプリをオススメしています。
文字化けってなった瞬間ショックを受けますよね~。ぜひ使ってみてください。
ただ、今回の技はかなり裏技的なだと思います。ほかに正式にやる方法があるのかもしれませんが、覚えておくと重宝すると思いますので。